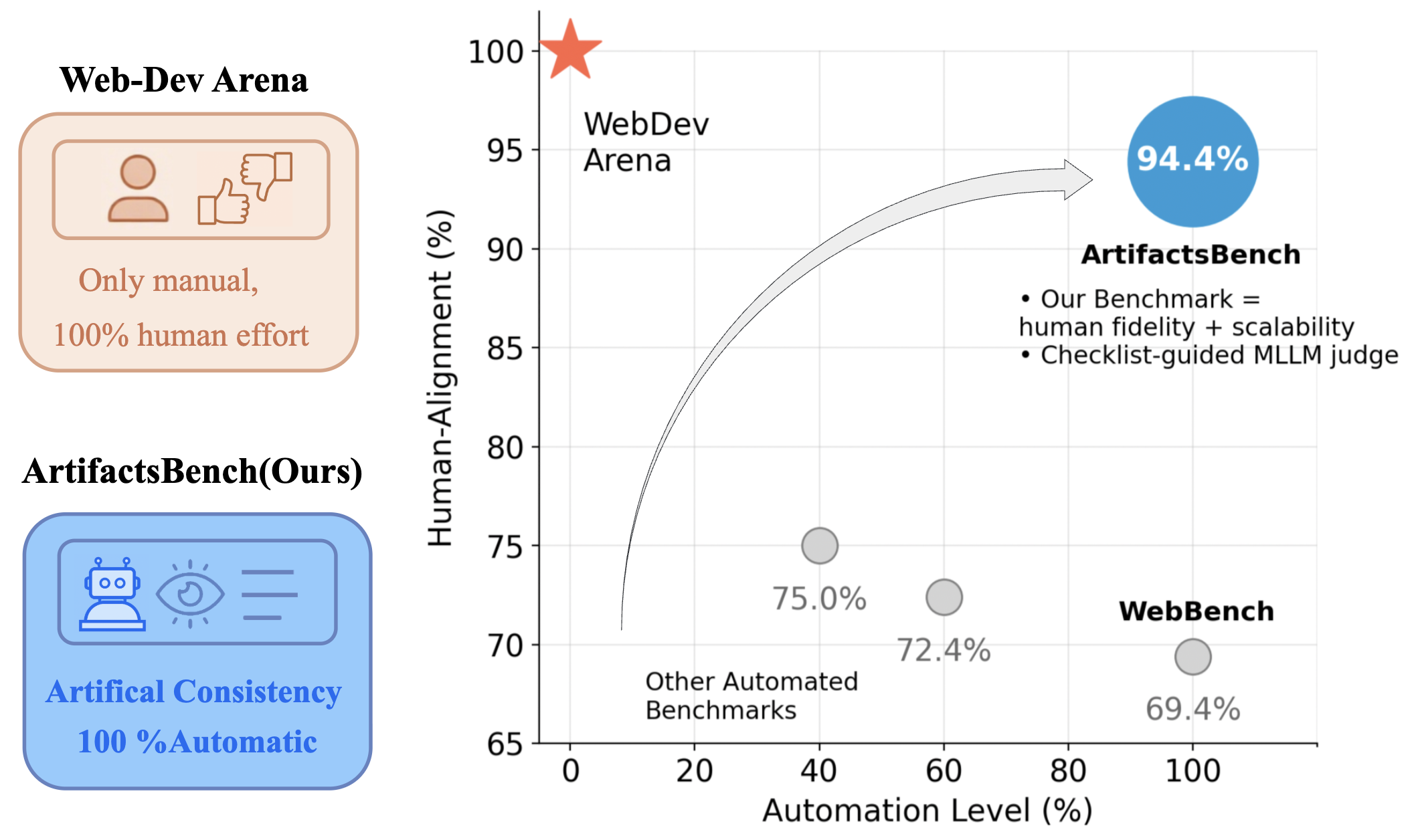
ArtifactsBench is the first automated multimodal evaluation benchmark for LLM-generated visual artifacts that renders dynamic outputs, assesses fidelity and interactivity using MLLM judges guided by fine-grained checklists, and achieves over 94% human preference correlation across 1,825 diverse tasks.
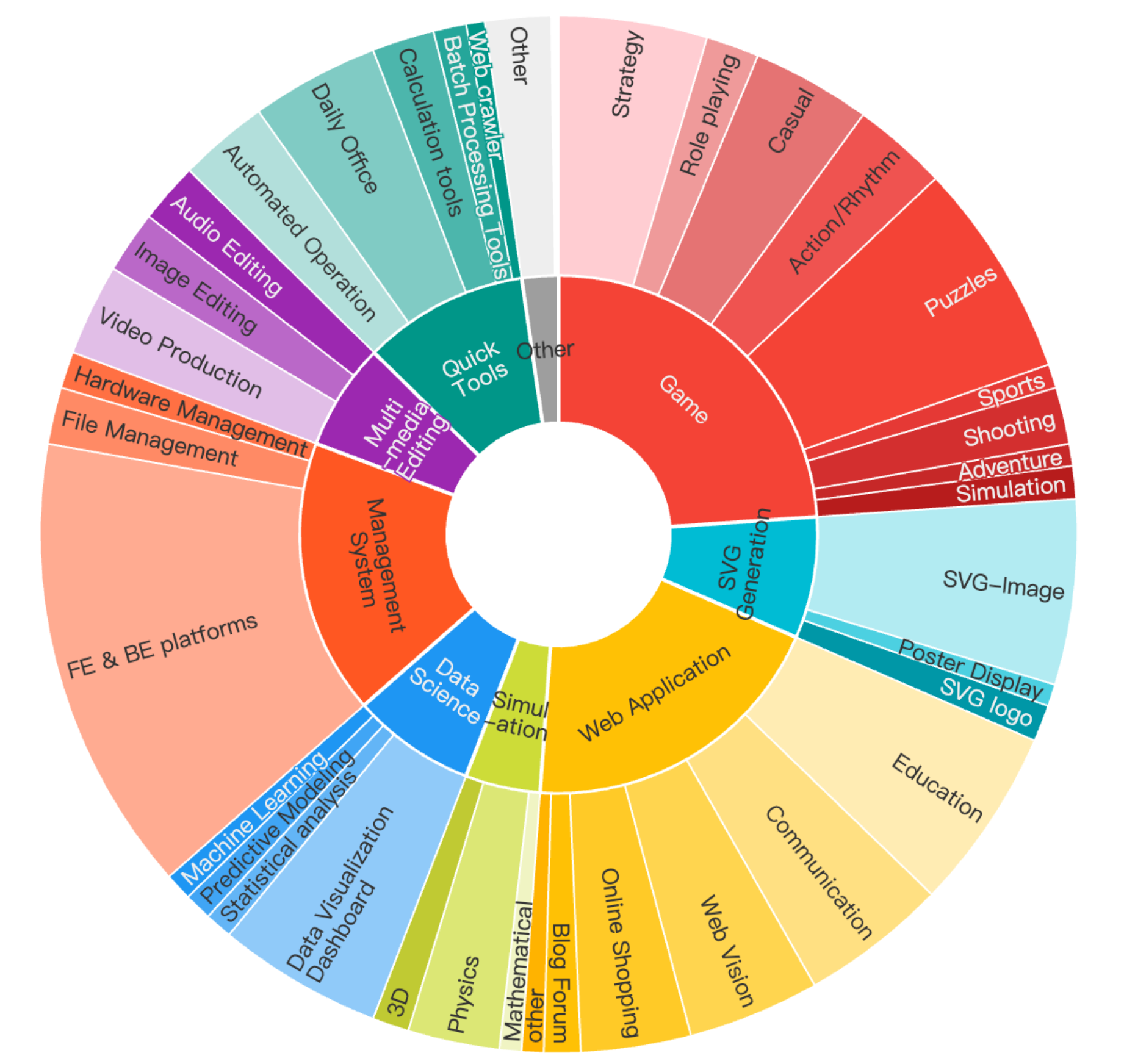
The ArtifactsBench benchmark comprises 1,825 high-quality, challenging queries organized into nine distinct categories: Game Development, SVG Generation, Web Applications, Simulations, Data Science, Management Systems, Multimedia Editing, Quick Tools, and Others. This structure ensures broad coverage of practical application domains.
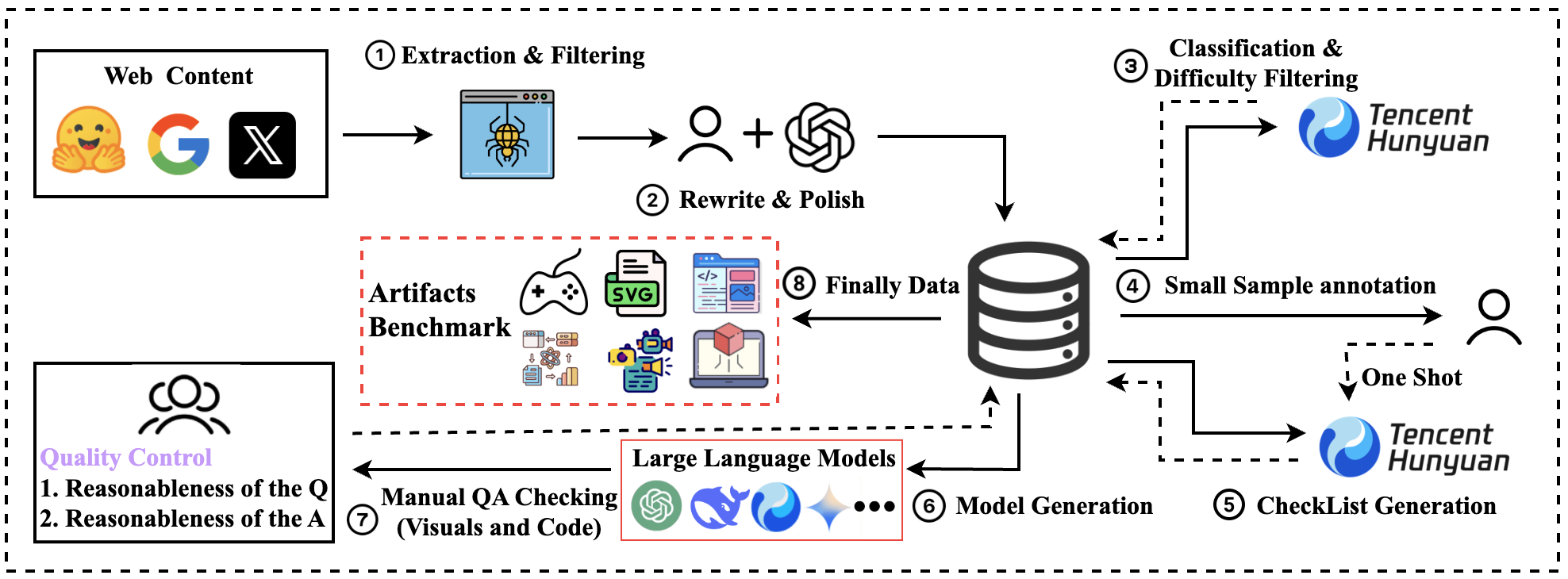
We organize ArtifactsBench creation as an eight-stage pipeline: Extraction & Filtering, Manual and LLM-based Rewrite & Polish, Classification and Difficulty Filtering, Small Sample Annotation, CheckList Generation, Model Generation, Manual QA Checking and Quality Control, and Final Data Consolidation. This structured process ensures the generation of diverse, high-quality tasks for robust evaluation of visual code generation.
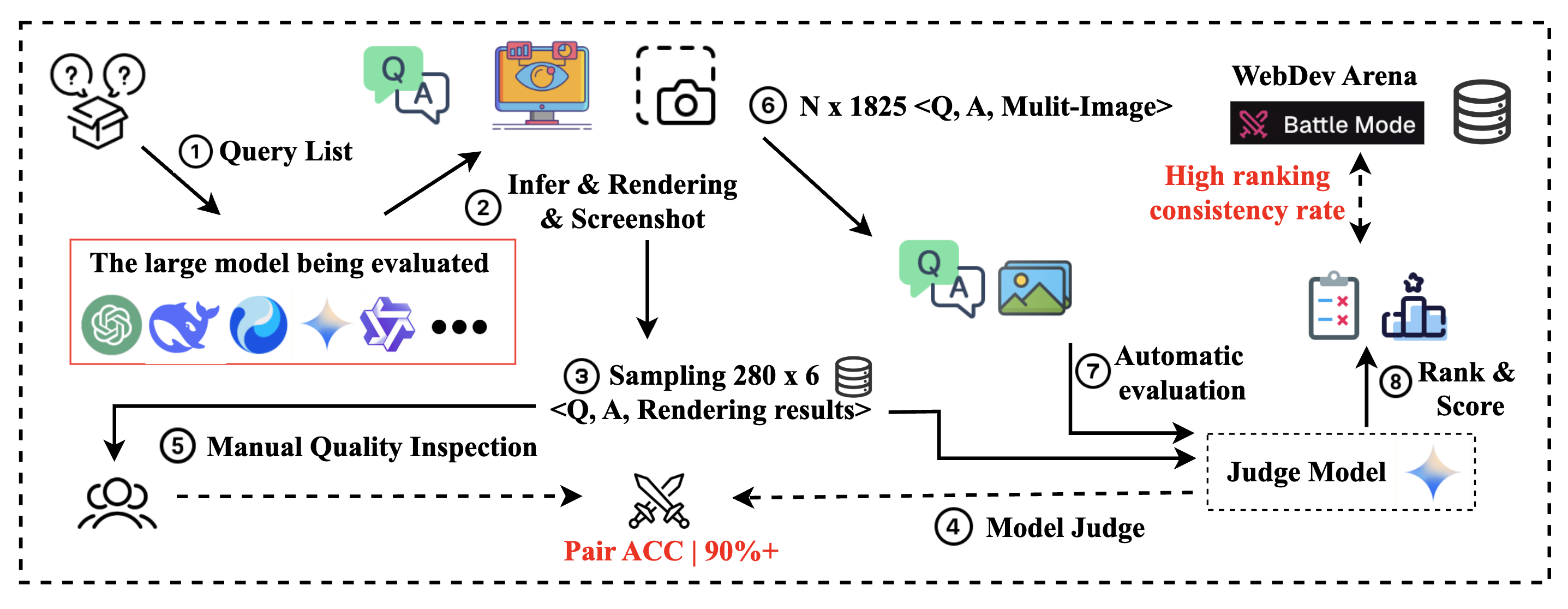
To ensure the validity of our evaluation framework, we first rigorously assess the MLLM-as-judge approach by measuring its pairwise scoring agreement with human experts on a carefully curated task subset. After confirming its high reliability (achieving >90% agreement), we then deploy this automated judge for large-scale evaluation across the entire benchmark. The scoring process follows a structured three-stage pipeline: (1) Code Extraction, (2) Dynamic Rendering and Capture, and (3) MLLM-as-Judge Assessment.
artifactsbench_vs_model_infer.png that visualizes the relationship between model inference scores and model response lengths, providing deeper insights into model behavior patterns.We're excited to announce important updates to ArtifactsBench that significantly improve reproducibility, expand model coverage, and enhance evaluation stability:
All intermediate model results, judge model inference results, and reasoning chains from this update are available at dataset/release_data_20250725/ for complete transparency and reproducibility.
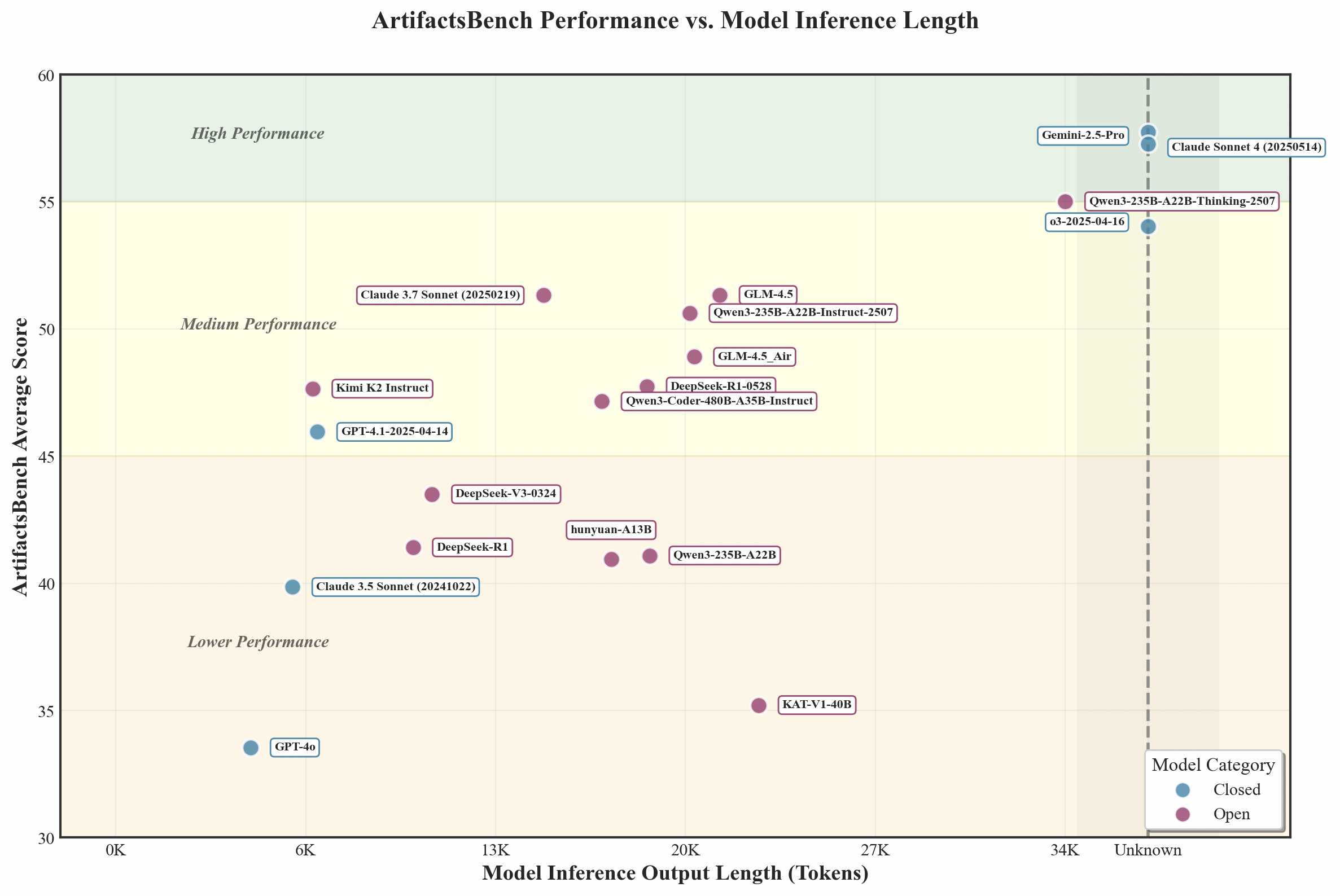
Figure: Analysis of model inference scores versus response lengths on ArtifactsBench, revealing the relationship between model performance and output verbosity patterns.
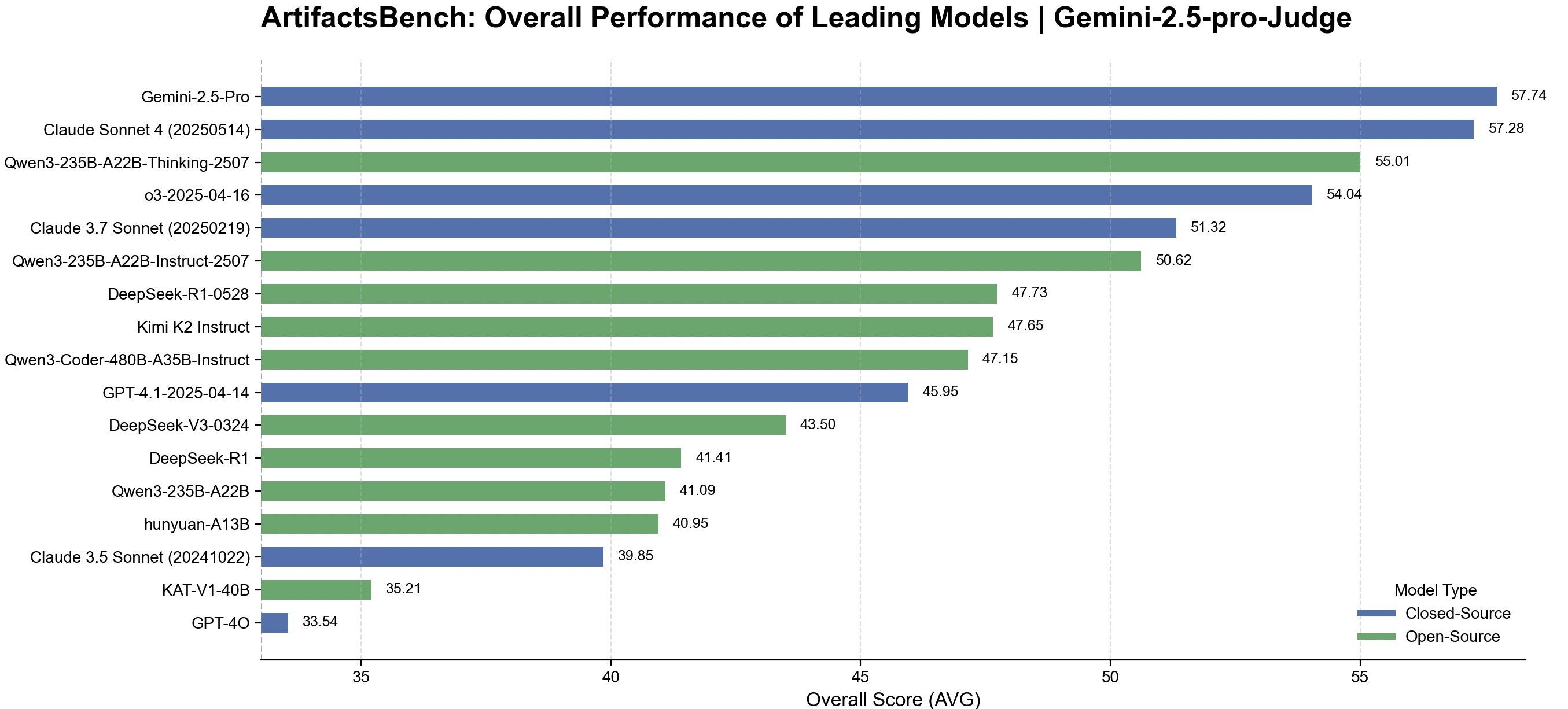
Figure: Latest ArtifactsBench results (July 2025) with expanded model coverage and unified Gemini-2.5-Pro evaluation.
For comparison, the previous results table is available in the Leaderboard section.
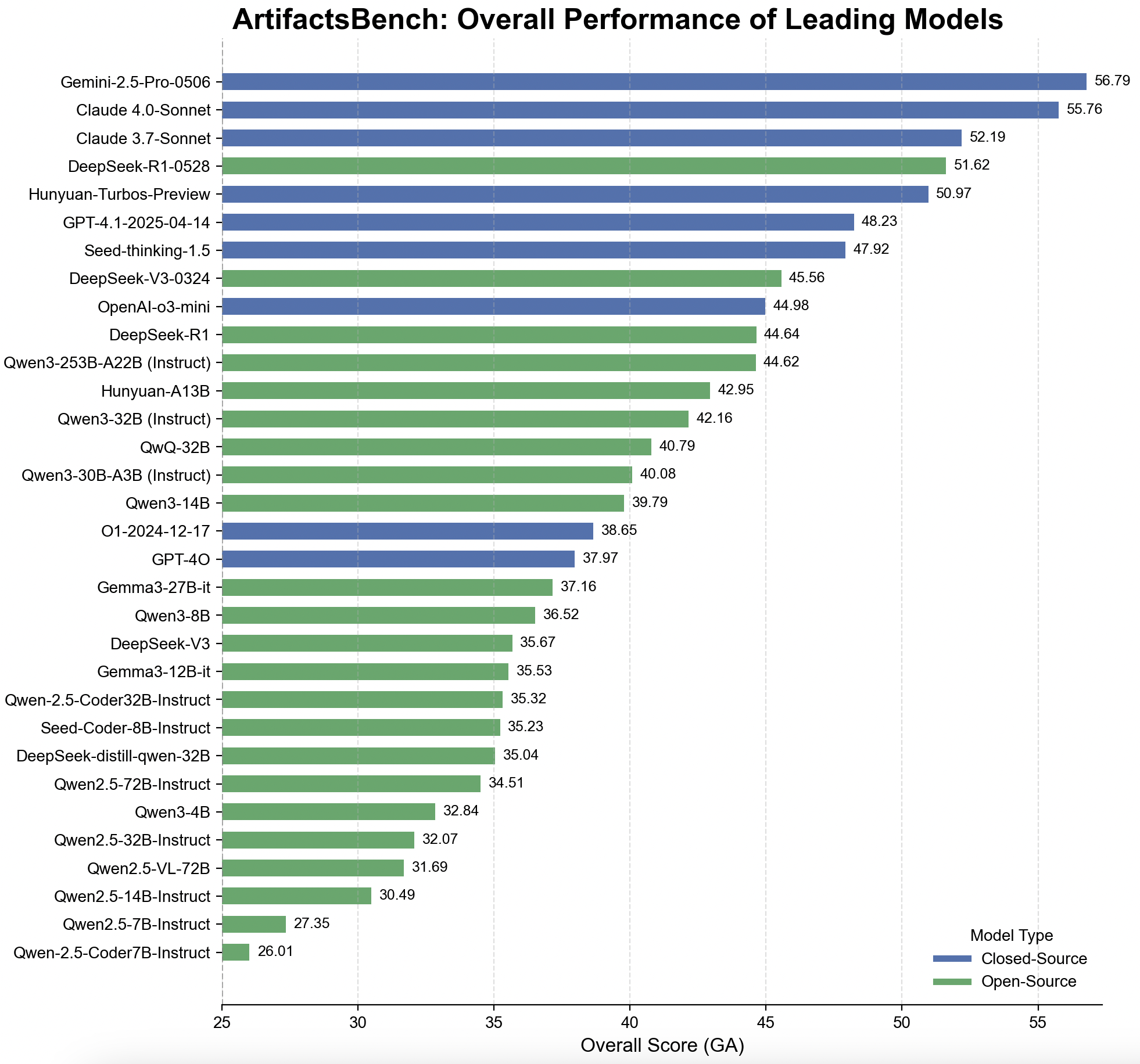
Our comprehensive evaluation covers over 30 state-of-the-art Large Language Models (LLMs), including both open-source and proprietary systems. The open-source cohort features 23 models spanning several influential families: the Qwen2.5 series, Qwen3 series, Gemma3 series, along with notable standalone models like Seed-Coder-8B-Instruct and the Deepseek series. For proprietary models, we evaluate 8 leading systems: Gemini-2.5-Pro-Preview-05-06, Claude 3.7 Sonnet (20250219), Claude 4 Sonnet (20250514), GPT-4o-2024-11-20, o3-mini-2025-01-31, Seed-thinking-1.5, and Hunyuan-TurboS-preview.
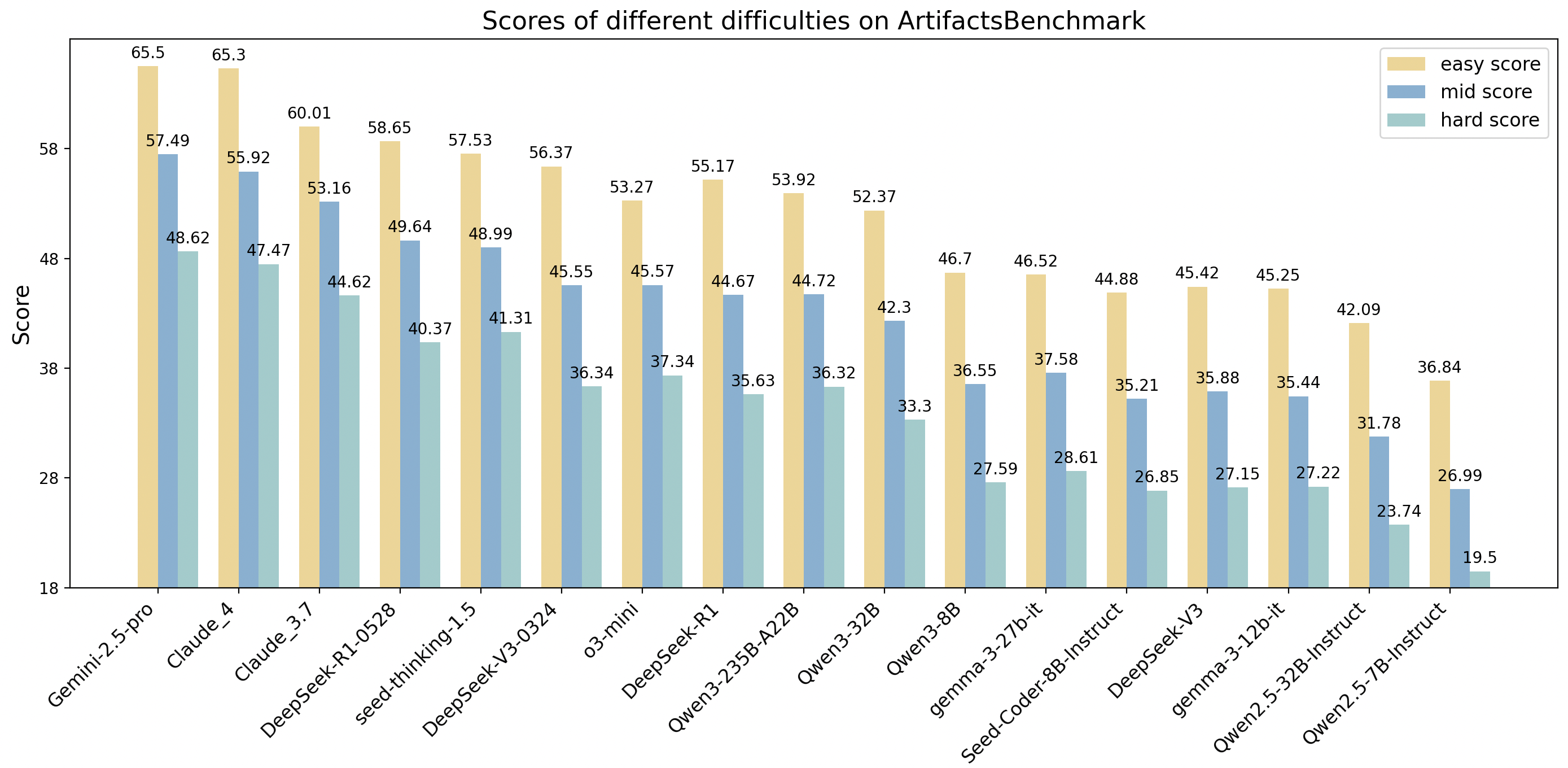
We organize the benchmark into three tiers of increasing difficulty. Even the best-performing models struggle to surpass 50 points on the most challenging subset, indicating that our benchmark remains far from saturation. Notably, the models' relative rankings remain consistent across all difficulty levels, and each tier maintains strong discriminative power—demonstrating our benchmark's ability to reliably differentiate model capabilities at every level of challenge.
We find that the model rankings from ArtifactsBench exhibit a remarkably high correlation with WebDev Arena, achieving a 94.4% consistency score. This score is calculated using the normalized Footrule metric, which quantifies the agreement between two ranked lists.
@article{zhang2025artifactsbench,
title={ArtifactsBench: Bridging the Visual-Interactive Gap in LLM Code Generation Evaluation},
author={Zhang, Chenchen and Li, Yuhang and Xu, Can and Liu, Jiaheng and Liu, Ao and Hu, Shihui and Wu, Dengpeng and Huang, Guanhua and Li, Kejiao and Yi, Qi and others},
journal={arXiv preprint arXiv:2507.04952},
year={2025}
}